

LERF- Language Embedded Radiance Fields
NeRF+CLIP
Intro
背景
- 神经辐射场 (NeRF) 已成为一种强大的技术,用于捕获复杂的现实世界 3D 场景的逼真数字表示。然而,NeRF 的直接输出只不过是一个彩色的密度场,缺乏意义或上下文,这阻碍了构建与生成的 3D 场景交互的界面。
- 自然语言是与 3D 场景交互的直观界面。考虑厨房的捕获。想象一下,能够通过询问“用具”在哪里来导航这个厨房,或者更具体地说,询问可用于“搅拌”的工具,甚至可以询问您最喜欢的带有特定功能的杯子。其上的徽标——贯穿日常对话的舒适和熟悉。这不仅需要处理自然语言输入查询的能力,还需要能够在多个尺度上合并语义并与长尾和抽象概念相关。
解决方案
一个Language Field
通过优化从现成的视觉语言模型(如 CLIP)到 3D 场景的嵌入,为 NeRF 中的语言奠定基础。
LERF 提供了一个额外的好处:由于我们从多个尺度的多个视图中提取 CLIP 嵌入,因此通过 3D CLIP 嵌入获得的文本查询的相关性图与通过 2D CLIP 嵌入获得的文本查询的相关性图相比更加本地化。根据定义,它们也是 3D 一致的,可以直接在 3D 字段中进行查询,而无需渲染到多个视图。
相较于Clip-Field[[CLIP-Fields- Weakly Supervised Semantic Fields for Robotic Memory]], LERF 更密集。
CLIP-Fields [32] and NLMaps-SayCan [8] fuse CLIP embeddings of crops into pointclouds, using a contrastively supervised field and classical pointcloud fusion respectively. In CLIP-Fields, the crop locations are guided by Detic [40]. On the other hand, NLMaps-SayCan relies on region proposal networks. These maps are sparser than LERF as they primarily query CLIP on detected objects rather than densely throughout views of the scene. Concurrent work ConceptFusion [19] fuses CLIP features more densely in RGBD pointclouds, using Mask2Former [9] to predict regions of interest, meaning it can lose objects which are out of distribution to Mask2Former’s training set. In contrast, LERF does not use region or mask proposals.
LERF
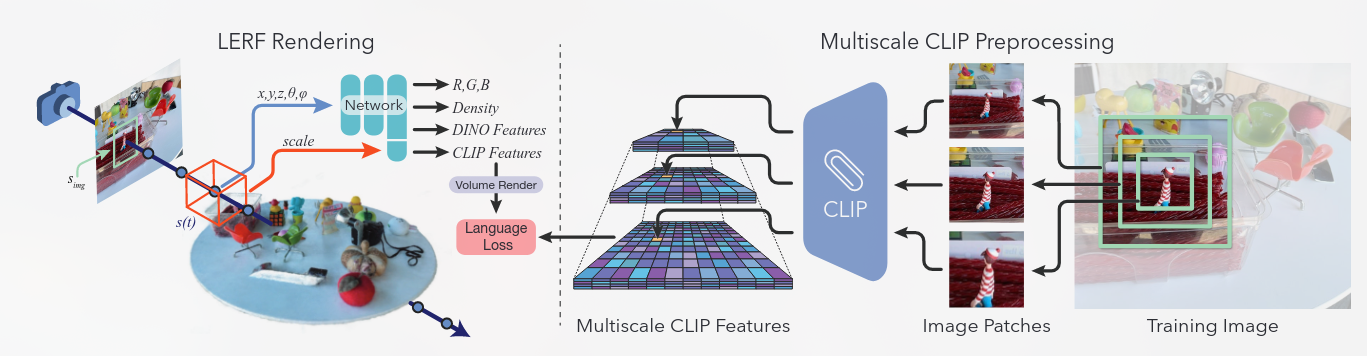
给定一组校准的输入图像,我们将 CLIP 嵌入到 NeRF 内的 3D 场中。然而,查询单个 3D 点的 CLIP 嵌入是不明确的,因为 CLIP 本质上是全局图像嵌入,不利于像素对齐特征提取。为了解释这一特性,我们提出了一种新颖的方法,该方法涉及学习以样本点为中心的卷上的语言嵌入领域。具体来说,该字段的输出是包含指定体积的图像作物的所有训练视图中的平均 CLIP 嵌入。通过将查询从点重新构造为体积,我们可以有效地从输入图像的粗裁剪中监督密集的字段,这些图像可以通过在给定的体积尺度上进行调节来以像素对齐的方式渲染。
LERF- Language Embedded Radiance Fields

